Introduction to Neural Networks
Data augmentation¶
The problem we're seeing here is caused by our training set being a bit restrictive. The network can only learn from what we show it, so if we want it to be able to understand black-on-white writing as well as white-on-black then we need to show it some labelled examples of that too.
If you're training your network to recognise dogs then you don't just want good-looking, well-lit photos of dogs straight on. You want to be able to recognise a variety of angles, lighting conditions, framings etc. Some of these can only be improved by supplying a wider range of input (e.g. by taking new photos) but you can go a long way to improving your resiliency to test data by automatically creating new examples by inverting, blurring, rotating, adding noise, scaling etc. your training data. This is known as data augmentation.
In general, data augmentation is an important part of training any network but it is particularly useful for CNNs.
Inverting the images¶
In our case we're going to simply add colour-inverted versions of the data to our training data set.
We use the Dataset.map() and Dataset.concatenate() methods to double up our training set with a set of images where all the values have been inverted in the range 0-1.
def invert_img(image, label):
return 1.-image, label
Then, to the data preparation, add in a line like
ds = ds.concatenate(ds.map(invert_img))
just after the image normalisation map.
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.concatenate(ds_train.map(invert_img)) # new line
ds_train = ds_train.shuffle(1000)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.concatenate(ds_test.map(invert_img)) # new line
ds_test = ds_test.batch(128)
If you then retrain the model:
model.fit(
ds_train,
validation_data=ds_test,
epochs=2,
)
You should see an improvement
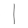




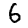
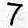



Summary¶
It's possible that you only see a small improvement and even a worsening on some examples. Particularly on the 9 example, the network will struggle as it doesn't really represent the training data set. Here are some things that may improve network performance:
- More data augmentation (brightness, rotations, blurring etc.)
- Larger base training set (colour images perhaps)
- Larger number of training epochs (in general, the more the better)
- Tweak the hyperparameters (dropout rate, learning rate, kernel size, number of filters, etc.)